- Como fazer backup dos exames de imagens de tomografia?
- Por que os arquivos DICOM são diferentes?
- O papel do servidor PACS no armazenamento
- Usar um NAS QNAP para o backup local
- A importância dos backups automáticos
- Replicação para um segundo local ou nuvem
- Fitas LTO ou nuvem para retenção prolongada
- Garantir a segurança com criptografia e LGPD
- Testes periódicos para validar a recuperação
- Os riscos ao usar HDs externos e soluções caseiras
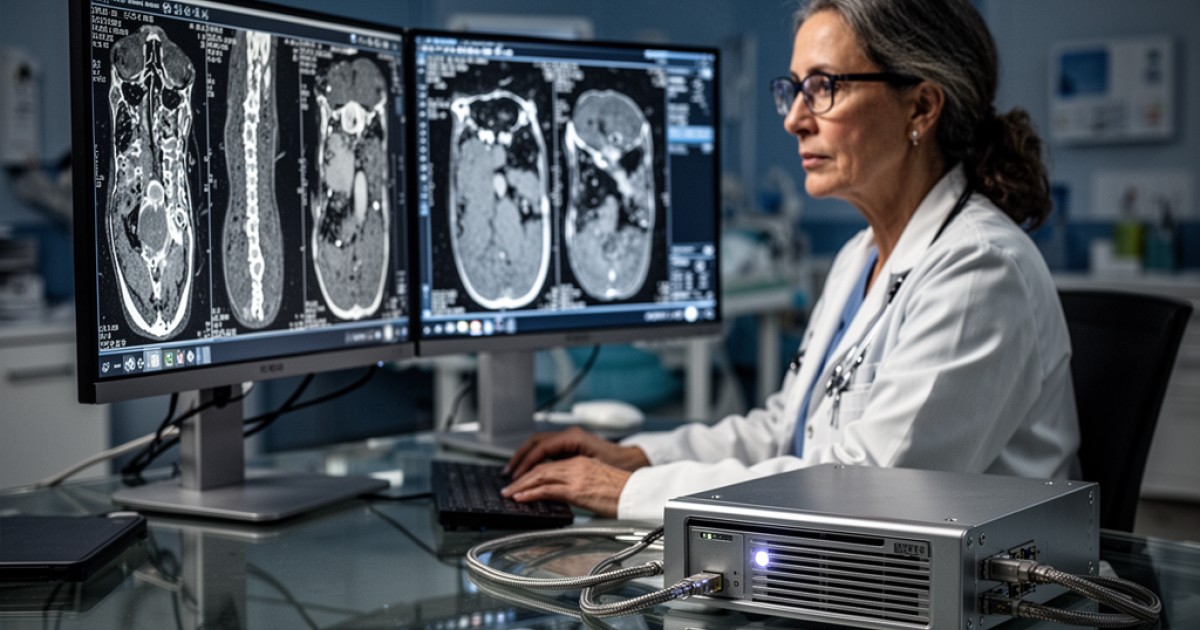
Clínicas e hospitais geram um volume imenso com exames por imagem todos os dias. Essa produção contínua exige muito espaço para armazenamento e também um gerenciamento cuidadoso dos dados. A perda desses arquivos causa problemas graves para a instituição e seus pacientes.
Um simples erro humano ou uma falha em um disco rígido pode apagar anos com históricos médicos. Isso resulta em prejuízos financeiros e ainda compromete a conformidade com as regulamentações sobre proteção aos dados. Muitos gestores subestimam esse risco até que seja tarde demais.
Assim, implementar uma rotina para cópias seguras não é um luxo, mas uma necessidade operacional. Um sistema bem estruturado protege os exames contra falhas, ataques e desastres, além de garantir a continuidade do atendimento.
Como fazer backup dos exames de imagens de tomografia?
O backup para exames de tomografia envolve criar cópias seguras e automáticas dos arquivos DICOM em um dispositivo separado, como um storage NAS. Esse processo segue a regra 3-2-1, que recomenda manter três cópias dos dados em dois tipos diferentes com mídias, com uma delas armazenada em um local externo. A estratégia deve incluir também a validação periódica das cópias para garantir a integridade e a rápida recuperação quando necessário.
Na prática, o software para backup acessa o servidor PACS, onde os exames ficam guardados, e copia os novos arquivos para o storage. Vários sistemas modernos executam essa tarefa sem qualquer intervenção manual após a configuração inicial. Isso minimiza bastante o risco com falhas humanas e assegura que as cópias estejam sempre atualizadas.
Além disso, uma boa política para backup define por quanto tempo cada exame será mantido. Alguns arquivos precisam ser guardados por muitos anos por força da lei. Por isso, o sistema deve suportar diferentes políticas com retenção para otimizar o uso do espaço e ainda atender as exigências legais.
Por que os arquivos DICOM são diferentes?
Os arquivos no formato DICOM são o padrão universal para imagens médicas. Eles são muito mais que simples fotografias. Cada arquivo contém, além da imagem em alta resolução, um conjunto extenso com metadados. Essas informações incluem o nome do paciente, a data do exame, o tipo do equipamento usado e até anotações do médico.
Essa estrutura complexa torna o arquivo DICOM único. Perder os metadados é quase tão ruim quanto perder a própria imagem, pois o exame perde seu contexto clínico e legal. Por essa razão, qualquer sistema para backup precisa preservar a integridade total do arquivo, sem alterar nenhuma informação.
Outro ponto importante é o tamanho desses arquivos. Um único exame com tomografia ou ressonância magnética pode facilmente ocupar vários gigabytes. Uma clínica de médio porte gera centenas com gigabytes ou até terabytes com novos dados toda semana. Essa característica exige soluções com alta capacidade e desempenho para o armazenamento.
O papel do servidor PACS no armazenamento
O servidor PACS é o coração do sistema para arquivamento e comunicação com imagens em uma unidade de saúde. Ele funciona como um grande repositório central que armazena, recupera, distribui e apresenta todas as imagens médicas. Médicos e técnicos acessam esse sistema para visualizar os exames de qualquer estação de trabalho na rede.
Quase sempre, o PACS é o ponto de partida para qualquer estratégia com cópias de segurança. Os dados primários residem nele, por isso o software para backup se conecta diretamente a esse servidor para copiar os arquivos. A integração entre o PACS e a solução para backup precisa ser fluida para não impactar o desempenho da rede durante o horário de trabalho.
Vale ressaltar que o backup não substitui o PACS. Pelo contrário, ele funciona como uma camada adicional de proteção. Enquanto o PACS oferece acesso rápido aos exames recentes, o sistema para backup garante a segurança a longo prazo e a recuperação em caso de uma falha grave no servidor principal.

Usar um NAS QNAP para o backup local
Um storage NAS QNAP é uma excelente escolha para centralizar o backup local dos exames. Esses equipamentos são servidores de armazenamento conectados à rede, projetados para funcionar 24 horas por dia. Eles oferecem alta capacidade, redundância com discos (RAID) e um conjunto robusto com softwares para automação.
Com um NAS, é possível configurar tarefas automáticas para copiar os arquivos do servidor PACS em horários específicos, geralmente durante a noite. O aplicativo Hybrid Backup Sync da QNAP, por exemplo, permite criar múltiplos jobs com backup, sincronização e replicação. Ele suporta diversos protocolos e garante que os dados sejam transferidos com segurança.
A configuração RAID em um NAS também protege os dados contra a falha de um disco rígido. Se um HD parar de funcionar, o sistema continua operando normalmente com os outros discos. Basta substituir o disco defeituoso para que a redundância seja restaurada, sem qualquer perda de dados ou interrupção no serviço.
A importância dos backups automáticos
Confiar em processos manuais para cópias de segurança é uma receita para o desastre. Alguém pode esquecer de executar a tarefa, conectar o dispositivo errado ou copiar os arquivos incorretos. A automação elimina completamente a dependência do fator humano e, consequentemente, reduz drasticamente a chance de erros.
Sistemas automatizados executam as cópias de forma consistente e previsível. É possível agendar backups para ocorrerem diariamente, semanalmente ou até de forma contínua, copiando os arquivos assim que são criados. Isso garante que o RPO (Recovery Point Objective) seja o menor possível, minimizando a quantidade de dados perdidos em uma falha.
Além disso, os sistemas automáticos geram relatórios detalhados sobre cada tarefa. Os administradores de TI recebem notificações por e-mail sobre o sucesso ou a falha de cada job. Essa visibilidade permite identificar e corrigir problemas rapidamente, antes que eles se tornem uma ameaça real para os dados.
Replicação para um segundo local ou nuvem
Manter um backup local em um NAS protege contra falhas de hardware e erros humanos, mas não contra desastres físicos. Um incêndio, uma inundação ou até mesmo um roubo do equipamento pode destruir tanto os dados originais quanto a cópia de segurança. Por isso, a regra 3-2-1 insiste em uma cópia externa.
A replicação de dados é o processo de enviar uma cópia do backup para outro local. Isso pode ser feito para um segundo NAS QNAP em outra filial da clínica ou para um serviço de armazenamento em nuvem. O Hybrid Backup Sync facilita essa tarefa, pois se integra nativamente com vários provedores como Amazon S3, Google Cloud e Microsoft Azure.
Ter uma cópia offsite é a apólice de seguro definitiva para os dados. Se o pior acontecer na unidade principal, será possível restaurar todos os exames a partir da cópia remota. Essa capacidade de recuperação de desastres é fundamental para a continuidade dos negócios e a segurança dos pacientes.
Fitas LTO ou nuvem para retenção prolongada
A legislação brasileira exige que prontuários e exames de pacientes sejam guardados por no mínimo 20 anos. Manter um volume tão grande de dados em discos rígidos de alto desempenho por tanto tempo é extremamente caro e ineficiente. Para o arquivamento de longo prazo, existem soluções mais adequadas.
As fitas magnéticas do tipo LTO (Linear Tape-Open) são uma opção tradicional e muito confiável. Elas possuem uma capacidade enorme, um custo por terabyte muito baixo e uma durabilidade que ultrapassa 30 anos. Muitos sistemas de backup, incluindo os da QNAP, suportam a integração com unidades de fita para mover dados mais antigos do NAS para o arquivamento em fita.
Outra alternativa moderna é o armazenamento em nuvem de categoria "archive". Serviços como o Amazon S3 Glacier Deep Archive oferecem um custo de armazenamento baixíssimo, ideal para dados que raramente serão acessados. A recuperação pode levar algumas horas, mas para fins de conformidade legal, essa solução é bastante eficaz e econômica.
Garantir a segurança com criptografia e LGPD
Exames de tomografia contêm informações de saúde sensíveis, protegidas pela Lei Geral de Proteção de Dados (LGPD). Um vazamento desses dados pode resultar em multas pesadas para a clínica, além de danos irreparáveis à sua reputação. Portanto, a segurança deve ser uma prioridade em toda a estratégia de backup.
A criptografia é uma ferramenta essencial para proteger esses arquivos. Os dados devem ser criptografados tanto em trânsito, durante a transferência pela rede, quanto em repouso, quando armazenados no NAS ou na nuvem. Os storages QNAP oferecem criptografia baseada em volume com o padrão AES de 256 bits, que impede o acesso não autorizado aos arquivos mesmo que os discos sejam roubados.
Além da criptografia, é fundamental implementar controles de acesso rigorosos. Apenas pessoal autorizado deve ter permissão para acessar os backups. Os sistemas QNAP permitem a criação de contas de usuário com diferentes níveis de privilégio e registram todas as atividades em logs de auditoria, o que ajuda a comprovar a conformidade com a LGPD.
Testes periódicos para validar a recuperação
Um backup que nunca foi testado é apenas uma suposição. Não há como ter certeza de que os dados estão íntegros e que o processo de restauração funciona, a menos que você o execute de verdade. Muitas organizações negligenciam essa etapa e só descobrem que seu backup estava corrompido quando mais precisam dele.
É recomendável realizar testes de recuperação em intervalos regulares, por exemplo, a cada trimestre. O teste consiste em selecionar um conjunto aleatório de exames do backup e restaurá-los para um local temporário. Em seguida, um técnico ou médico deve tentar abrir os arquivos para confirmar que eles estão legíveis e completos.
Esses testes validam a eficácia de toda a estratégia. Eles confirmam que o hardware está funcionando, que o software está configurado corretamente e que os dados estão sendo copiados sem corrupção. Documentar os resultados de cada teste também é uma boa prática para fins de auditoria e conformidade.
Os riscos ao usar HDs externos e soluções caseiras
Algumas clínicas menores, na tentativa de economizar, recorrem a HDs externos USB para fazer o backup dos exames. Essa abordagem é extremamente arriscada e inadequada para um ambiente profissional. Discos externos não possuem redundância, são frágeis e dependem de um processo manual, que é inerentemente falho.
Um único HD externo representa um ponto único de falha. Se ele cair no chão, for infectado por um ransomware ou simplesmente parar de funcionar, todos os dados de backup serão perdidos. Além disso, a falta de automação significa que as cópias raramente são feitas com a frequência necessária, deixando uma grande janela de exposição a perdas.
Soluções caseiras também carecem de recursos de segurança como criptografia e controle de acesso. Um HD externo pode ser facilmente perdido ou roubado, expondo informações confidenciais de centenas de pacientes. Diante dos requisitos legais e da importância dos dados, investir em uma solução profissional como um NAS QNAP não é um custo, mas uma proteção para o negócio. Para proteger exames de tomografia, um sistema de armazenamento em rede é a resposta.
Não perca mais tempo: fale AGORA com um especialista!
Tire suas dúvidas sobre backup e recuperação em minutos e descubra como podemos ajudar você ainda hoje. Atendimento rápido e direto pelo WhatsApp.
QUERO FALAR NO WHATSAPP


